Як знайти відсутню сутність — і як вона стала точкою перетину всього продукту

У цій статті:
Кілька років тому в нас була проста проблема. Інформація про куратора курсу заповнювалася на кожному лендингу вручну: фото, ім'я, опис, місце роботи, окремо під кожну сторінку і в кожній мовній версії. А ще була окрема секція автора програми. Часто це була та сама людина.
Коли куратор змінював роботу або оновлював фото, хтось мав пройтися по всіх сторінках і виправити це руками. Тримати такий контекст у голові неможливо, тому насправді цього не робив майже ніхто. Виправляли лише тоді, коли хтось показував на застарілу інформацію. Так і жили: на одному курсі в людини одне фото, на іншому інше, тут одна посада, там інша, ще й різна транслітерація імені. Одна персона, а контент скрізь різний. Дуже тягне душком несистемності.
На поверхні це виглядало як контентна проблема. Насправді — архітектурна.
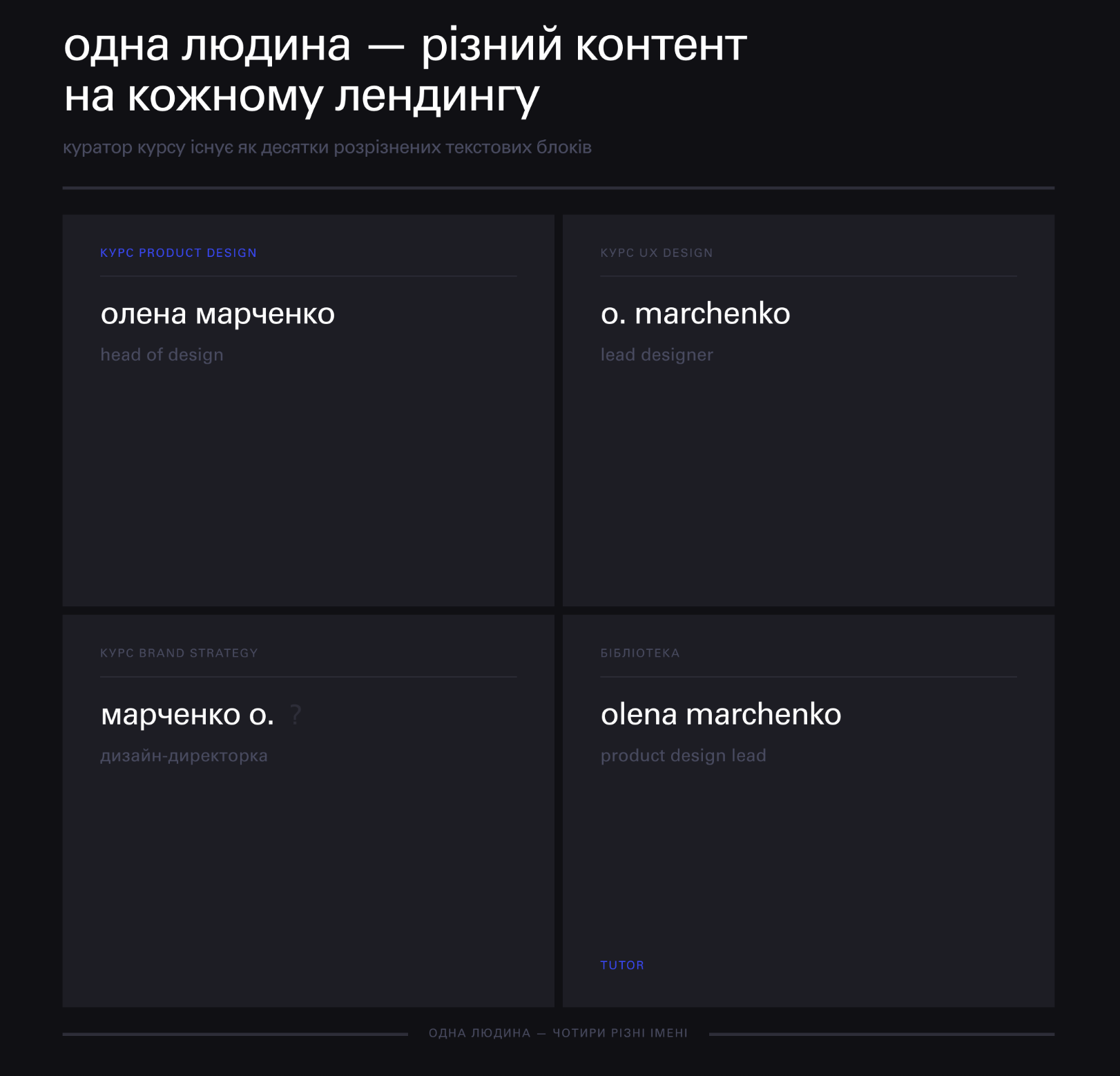
Симптом і причина живуть нарізно
Найбільше за роки роботи мене захоплює одне спостереження: причина і симптом проблеми майже ніколи не живуть поруч. Симптом сидів на лендингах. Причина ховалася значно глибше.
Найпростіше було міркувати рівнем фічі. Зробити зручніший інтерфейс редагування. Може, окремий блок в адмінці, шаблон чи новий процес для контент-менеджерів. Кожен із цих варіантів лагодить симптом і не чіпає причину.
А потім я зупинився на думці, яка змінила напрямок. У системі не існувало поняття «ця людина». Одна персона могла бути куратором одного курсу, лектором іншого, автором програми третього, ментором на менторській платформі, спікером на події. Але жила вона як десятки розрізнених текстових блоків, ніяк між собою не пов'язаних.
«Це була не контентна проблема. Це була відсутня сутність.»
Тому перше, що ми зробили, навіть не торкалося інтерфейсу. Ми створили tutor як окрему повноцінну сутність у системі.
Неймінг як архітектурна стеля
Назва сутності визначила все, що сталося далі. Ми могли назвати її curator, адже початкова задача була саме про кураторів курсів. Логічний і вузький вибір.
Але куратор — це лише роль. А в нашій екосистемі людина має багато ролей одночасно. Тому я заклав ширшу модель:
- tutor. Людина, яка передає знання в екосистемі.
- Роль. Ким вона є в контексті курсу: куратор, лектор, автор програми. Ці ролі не взаємовиключні.
- Контекст. Зв'язки в інших напрямках: менторство, бібліотека, події, спільнота.
Назви curator вистачило б рівно на один сценарій. Архітектурну стелю ми заклали б у перший день. Правильний неймінг на старті працює як стратегія: він визначає, як сутність сприйматимуть і перевикористовуватимуть далі.

Міграція, яка зробила аудит за нас
Створити сутність — найменша частина роботи. Щойно вона була готова, постало питання: звідки взяти дані? Об цей камінь спотикається кожен, хто вперше проєктує систему. Ейфорія «фіча зроблена» швидко змінюється тверезою реальністю: без даних вона нікому не потрібна.
Психологічно найбезпечніше було б посадити людей вручну переносити кураторів із лендингів у нову адмінку. Але це лікувало б системну проблему ще більшою кількістю ручної роботи. І відштовхнуло б колег від рішення, яке має їм допомагати.
Тому ми взяли роботу на себе через інженерні присідання. План був простий і чистих даних не гарантував, зате прибирав рутину:
- Крок 1. Витягнули сирий контент із вебсторінок.
- Крок 2. Знайшли патерни в текстових полях.
- Крок 3. Розпарсили дані й розклали на стовпці.
- Крок 4. Базовими можливостями таблиць і GPT-3.5 оцінили якість даних і знайшли дублікати.
- Крок 5. Видалили очевидні неякісні дублі.
- Крок 6. Імпортували як первинне наповнення.
А далі сталося найцікавіше. Міграція впала.
І це було найкраще, що могло статися. Скрипт зробив аудит за нас: він стикнувся з тим, що одна людина має дублікати в одній мові, з різними описами, фото й версіями імені. Скрипт не знав, яку версію записати основною, тому зупинявся й логував усе, що не зміг обробити. Цей список уже дотискала людина.
Так ми отримали запобіжник у два шари: [людина + AI] і [правила міграції + логи]. Міграція підсвітила проблему значно швидше, ніж зробили б це люди вручну. А залучали ми їх по мінімуму, лише на окремих етапах.
Був і простіший на вигляд шлях: залити дані як є й чистити вже всередині інтерфейсу. Теж підхід. Але якісно він працює тільки з масовими діями та злиттям профілів, а будувати їх на старті означає овер-інжиніринг. Інженерна міграція дала те саме очищення дешевше, а аудит якості став її побічним продуктом.
Найнебезпечніший момент — коли фіча вже працює
Після міграції в нас були нормалізовані дані й перше живе джерело. Разом із командою courses care ми налагодили процес: тютори створюються, лінкуються до курсів, оновлюються і деактивуються. Запрацював прошарок даних у розрізі курсів, персон і ролей. З'явилася перша статистика і придатні для AI дані.
І саме тут ховається пастка, в якій тихо вмирає більшість інфраструктурних проєктів. Широку потребу ми закрили: дані доступні, зв'язки є. А от вихідний біль, ручне наповнення лендингів, на той момент ще нікуди не подівся. Для менеджерів новий процес якийсь час виглядав як процес заради процесу.
Коли люди не відчувають, що рішення полегшує їм роботу, вони починають ним нехтувати. Адопшен згасає поступово й непомітно. А потім доводиться платити двічі: запускати все наново й доливати дані, які вчасно ніхто не вніс.
Урок простий і неприємний. Цей таймлайн не можна перетримати: його треба вчасно розпізнати, спланувати послідовність і ресурси, відкрито проговорити все з кожним, кого це зачіпає. І набратися терпіння, поки цінність стане відчутною.
Як одна сутність обростає зв'язками
Вихід із пастки був один: зробити сутність по-справжньому корисною. Якщо зупинитися на нормалізованому довіднику, tutor так і лишиться гарною таблицею. Справжня цінність почалася там, де він став точкою перетину з рештою екосистеми. Кожен новий зв'язок робив конструкцію міцнішою.

Менторство: коли сесія стає зв'язком, а не рядком
Першим великим перетином стала менторська платформа. Я називаю її «поряд створеним продуктом»: ідейно вона про те саме, що й курси, а технічно живе в іншому всесвіті, на Webflow із модулем бронювання. Ментор — це та сама людина, що несе знання, просто інакше. Менті фактично той самий студент.
Найпростіше рішення: ловити вебхук про кожен запис на сесію й складати його в окрему таблицю. Дві години роботи, і начебто готово. Але що ми отримали б? Рядок «Віктор Я. записався до Віктора Ю.». Система знає, що сесія була, але не знає, хто ці двоє в екосистемі Projector. Обидва існують як текст, а не як сутність.
Синхронізацію зробили через Make: щойно на платформі з'являється новий ментор, система мапить його з базою за певними ознаками. Є людина в базі, профіль доповнюється. Немає – створюється новий tutor, і дані пишуться в нашу БД без жодної ручної дії.
Цінність тут не в ще одній таблиці. Менторство стало одразу кількома речами: найдоступнішим автоматичним джерелом нових тюторів і даних про персон, джерелом нових студентів-лідів, контекстом намірів кожного, хто записується на сесію, та ідентифікованими менторами й менті, а це надцінне знання для маркетингу й операційки. Саме звідси екосистема почала набувати рис єдиного джерела правди. А сесія з рядка тексту перетворилася на зв'язок: студент → сесія → тютор.
Лендинги, каталог і SEO за іменами
Коли даних стало досить, ми перевели лендинги курсів з ручного контенту на динамічне підтягування профілю. Раніше це було нетривіально: контент складався в JSON, з якого формувалася HTML-сторінка, і підтягнути туди дані з бекенду просто так не виходило. Тому якийсь час стара й нова секції жили паралельно, а менеджери курсів перевіряли підтягнуті дані й правили сам профіль тютора замість окремої сторінки.
Відтоді будь-яка зміна (фото, опис, місце роботи, ім'я) оновлюється одразу скрізь, де є зв'язок. На цій же сутності ми зібрали каталог тюторів: понад тисячу сторінок з унікальним контентом про реальних людей. Ім'я, фото, опис, соцмережі, курси, де людина викладає чи є автором, можливість записатися до неї як до ментора.
А далі несподіваний ефект: SEO за іменами. Шукаєте, скажімо, Стаса Говорухіна, і у видачі поряд із LinkedIn з'являється сторінка Projector. Людина бачить, які курси він веде, що він ментор, і може записатися на сесію або придивитися до курсу. Кожна картка тютора на лендингу курсу стала клікабельною, і ми отримали внутрішню перелінковку між курсами й профілями.
Той самий маппинг, який ми будували заради даних, відкрив ще одну можливість: підключити віджет онлайн-букінгу менторської сесії прямо на сайті Projector. Механіка не змінилась, просто спрацювала вдруге. На той момент Projector уже став source of truth з ідентифікаторами в усіх системах, а цього виявилось достатньо, щоб той самий віджет, що стояв на менторській платформі, запрацював і на сторінці тютора.
Наповнення теж не з'явилося одним релізом. Спершу підтягнули середню вартість менторської сесії, потім — конкретний опис того, чим людина може допомогти. Профіль дозрівав поступово.
А це вже відкриває наступний крок. Маючи статистику, можна працювати над сторінкою тютора v2 — показувати не лише хто ця людина, а й що вона зробила: скільки студентів навчила, скільки курсів і груп провела, скільки менторських сесій відбулося, скільки донатів зібрано.
Блог, події та амбасадори
Далі та сама логіка повторювалася на кожній новій фічі. Блог-базу знань ми переносили з Webflow у систему. Можна було знову зробити автора статті текстовим полем і повторити стару помилку. Ми зробили інакше: автор статті — це tutor. Тепер статті з'являються в профілі людини, а блог отримав зв'язок із курсами й менторством.
Потім прийшли події. Ми ввели правило: спікер на події завжди тютор у системі. Саме правило, без винятків і обхідних шляхів. Кожна нова людина, яка виступає, автоматично потрапляє в граф і збагачує його. Так само з'явилася ознака амбасадора, людини, яка проводить локальні події. І вона живе в тому самому профілі.
Якщо людина перестає бути активним ментором, профіль нікуди не зникає. Деактивується лише конкретний модуль. Сутність лишається стабільною, а ролі й зв'язки змінюються вільно. От саме тому її майже неможливо зламати: вона тримається на багатьох процесах одразу.
Дані, які чекають на AI
Коли ми прив'язали тюторів ще й до груп, поверх контенту виросла аналітична модель. Тепер можна відповісти машинно на питання, які раніше жили по окремих таблицях: хто вів конкретну групу, які студенти в кого вчилися, скільки груп випустив куратор, скільки менторських сесій він провів, як давно він у системі.
На цьому класі даних тримається внутрішня аналітика: персональна статистика тютора на його сторінці, перформанс курсів, активність на менторських сесіях у BigQuery. Дані нормалізовані, пов'язані, історичні, тобто саме той формат, який потрібен для AI-аналізу всього бізнесу. Сьогодні tutor перетинає лендинги, менторську платформу, блог, події, каталог і аналітику, тобто сім із гаком частин продукту. Скоро сюди доєднаються відео з бібліотеки.
Три питання до будь-якої нової сутності
З цього кейсу я виніс простий фреймворк. Три питання, які варто поставити, перш ніж проєктувати нову сутність.
- Хто ще це споживає? Якщо відповідь «тільки цей модуль», перед вами радше фіча, ніж сутність. Якщо три різні команди в трьох контекстах, це вже вузол, навколо якого можна будувати.
- Що до цього можна прив'язати в майбутньому? Будувати все одразу не треба. Але архітектура не повинна зачиняти двері наперед. Якщо ви не уявляєте, як до сутності приєднається наступна фіча, зі схемою щось не так.
- Чи ламається щось, якщо це росте? Добре спроєктована сутність від надбудови не ламається, а міцнішає. Кожен новий зв'язок робить її ціннішою.
Тут є важлива чесна частина. Сутність без даних нікому не потрібна, а дані не з'являться без впровадження. Ми свідомо почали накопичувати їх заздалегідь, ще до того, як команди побачили практичну користь. Окремий виклик у тому, щоб донести цінність наперед, не стати балаболом і дотиснути скоуп до кінця.
Якщо ви відчуваєте, що в системі щось «не так»: дані дублюються, одна людина існує в кількох місцях різними текстами, кожна нова фіча тягне за собою ще один ручний процес, то, можливо, річ не в інтерфейсі і не в контенті.
Можливо, у вашій системі є відсутня сутність. І якщо знайти її та спроєктувати правильно, вона стане точкою перетину всього, що буде далі.
створюйте продукти які вражаютьна курсі

| досвід | робота в IT-сфері |
|---|---|
| старт навчання | 30.07.2026 |
| кількість місць | 20 |
| тривалість курсу | 4 місяці |
| бонус | безоплатний доступ на 4 місяці до бібліотеки Projector |
| куратор | Віта Максимець |
перший крок за вами
розширюйте свої можливості в PRзавдяки новим знанням
пошук сутності у продуктіпідсумуємо
- Що таке master data management і до чого тут edtech-платформа?
- Що таке source of truth і навіщо його створювати?
- Чим сутність (entity) відрізняється від звичайного текстового поля чи таблиці?
- З чого почати проєктування архітектури даних (data architecture) для нової продуктової сутності?
ще цікаведля вас









