Автоматизації що не множать хаос: як підготувати процес до MVP

У цій статті:
- [01]Як зрозуміти, що задача готова до автоматизації
- [02]Як обрати першу автоматизацію (а не найважливішу)
- [03]Як описати поточний процес (as-is, без прикрас)
- [04]Як розподілити відповідальність за RACI
- [05]Як налагодити Source of Truth
- [06]Як перевірити технічну реальність
- [07]Як спроєктувати логіку MVP
- [08]Чек-лист, який я проганяю перед Make / n8n
Моя перша автоматизація прожила в проді менше дня.
Я була впевнена, що проблема в Make. Зламалося розгалуження, потім фільтр, потім закінчилися токени. Я гасила пожежі ніч, ранок і ще пів дня, поки не зрозуміла дуже просту річ. Проблема не в Make — я почала збирати автоматизацію раніше, ніж підготувала процес.
Це стаття про те, що я роблю до того, як взагалі відкрию Make / n8n. Нудний, неромантичний етап. Він не дає тих самих ендорфінів, що перший спрацьований сценарій. Але саме він економить найбільше часу, нервів і грошей — у моєму досвіді він окуповується десятиразово.
Один принцип, до якого я постійно повертаюся: автоматизація — це підсилювач, не лікар. Вона множить існуючий стан процесу: і добрий, і кепський. Якщо процес кривий — у масштабі він стане ще кривішим. Це закономірність.
Як зрозуміти, що задача готова до автоматизації
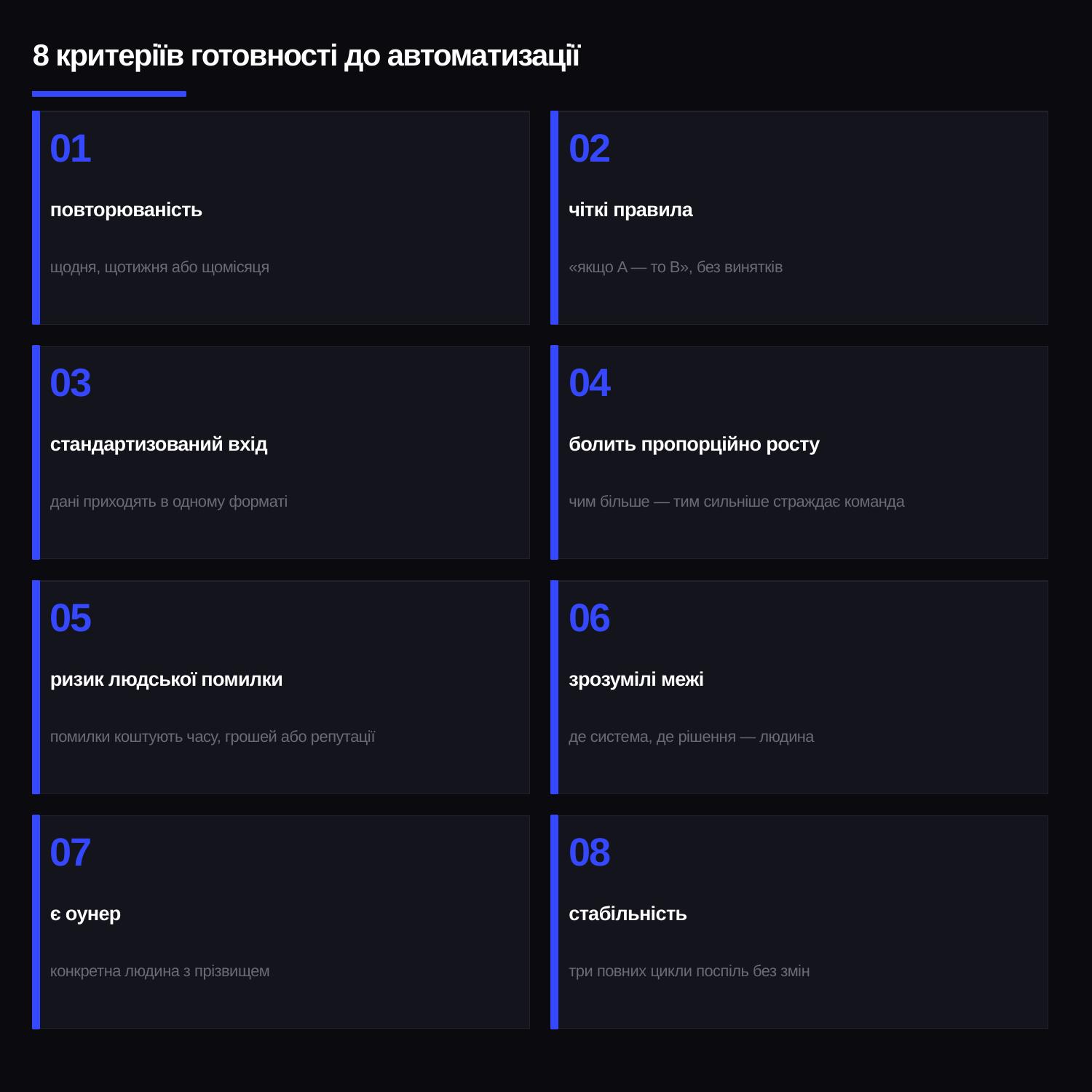
Якщо задача провалює три і більше з восьми критеріїв готовності — її ще зарано автоматизувати. Спочатку треба попрацювати з самим процесом. Перш ніж заходити в шаблон чи в Make / n8n, я проганяю задачу через цей чек-лист.
- Повторюваність. Дія виконується щодня, щотижня або щомісяця. Якщо це разовий кейс або «раз на квартал на свято» — не варто. Автоматизація окуповується тільки тоді, коли її запускають часто.
- Чіткі правила. Процес можна описати у форматі «якщо A — то B». Без винятків і без «ну тут зазвичай питають Колю, а Коля сам вирішує». Якщо логіка тримається на людському судженні — спочатку формалізуємо, потім автоматизуємо.
- Стандартизований вхід. Дані приходять в одному форматі. Один клієнт — один запис у формі, не три повідомлення в Telegram, два листи й один скріншот у Slack.
- Болить пропорційно росту. Чим більше клієнтів, заявок або студентів — тим сильніше команда страждає. Якщо біль не масштабується, задача не дозріла.
- Ризик людської помилки. Хтось забув оновити, скопіював не туди, надіслав не тому. Помилки коштують часу, грошей або репутації — а ручний контроль уже не масштабується.
- Зрозумілі межі. Я знаю, де автоматизація зупиняється і де рішення приймає людина. Якщо мені здається, що «AI все вирішить сам» — це червоний прапор, а не план.
- Є оунер. Конкретна людина, яка володіє процесом. Не «команда», не «той, хто збере сценарій» — одна людина з прізвищем.
- Стабільність. Процес стабільно проходить три повних цикли поспіль без істотних змін. Якщо логіка змінюється раз на тиждень — він ще не дозрів до автоматизації.
Останній критерій я додала після другого свого фейлу. Восьмий, мабуть, найважливіший: чек-лист — це чіткий фільтр між хаосом і готовністю. Не індульгенція автоматизувати все підряд.
Як обрати першу автоматизацію (а не найважливішу)
Першу автоматизацію беруть там, де максимальне співвідношення цінності й складності — щоб дати собі швидкий результат і впевненість для наступних. У мене зазвичай одночасно є 5–8 ідей для автоматизації. Усі виглядають корисними. Але мій час, бюджет на Make та АІ — обмежені, тому з них треба вибрати одну.
Я використовую дуже спрощений ICE-скоринг. На одну ідею — три цифри від 1 до 10:
- Impact. Скільки часу, грошей або нервів економить за місяць.
- Confidence. Наскільки я впевнена, що автоматизація реально спрацює.
- Effort. Наскільки легко її побудувати — тут логіка обернена: 10 = легко, 1 = пекло.
Множу. Сортую. Беру топ-1.
Простий приклад з мого досвіду. У мене була ідея автоматизувати персоналізовані листи-нагадування студентам, які не зайшли в LMS після старту курсу.
Impact = 8 (прямий вплив на утримання). Confidence = 6 (я не була впевнена, що моя сегментація правильна). Effort = 5 (треба було звʼязати LMS, CRM і email-сервіс). Підсумок: 240.
Інша ідея — автоматизувати щотижневий звіт для команди. Impact = 4 (зекономить мені дві години на тиждень). Confidence = 9 (точно спрацює). Effort = 9 (десять хвилин у Make / n8n). Підсумок: 324.
Я взяла другу. Чому? Вона дала мені швидкий результат і впевненість для першої ітерації. До листів-нагадувань я повернулася через місяць — уже з іншим рівнем досвіду в побудові автоматизацій.
Як описати поточний процес (as-is, без прикрас)
Реальний процес майже ніколи не дорівнює описаному — і автоматизувати треба саме реальний, з усіма його костилями. Це мій улюблений етап і найбільш недооцінений.
Перед автоматизацією я завжди описую процес таким, яким він працює зараз. Не таким, як він описаний у Notion. Не таким, як я б хотіла, щоб він працював.
А реальним — з костилями, ручними правками, повідомленнями в DM, експортом в CSV, який роблять «бо так склалося». Це боляче. Бо коли описуєш процес чесно — бачиш, скільки в ньому хаосу.
Я роблю це у простому шаблоні з полями: назва процесу, мета, фінальний артефакт, тригер, регулярність, учасники й зони відповідальності. Окремо — таблиця поточних кроків: крок, хто робить, вхід, вихід, інструмент. Плюс Source of Truth, болеві точки, попередні гіпотези щодо меж.
Ключ — у колонці поточні кроки. Кожен рядок там — це майбутній модуль у Make / n8n. І саме тут зазвичай вилазить уся правда.
Перш ніж щось автоматизовувати, переконайся, що ти взагалі розумієш, що відбувається.
У нашої команди є процес обробки заявок на B2B-партнерство. В Notion звучав як «пʼять чітких кроків». Коли я почала описувати його чесно — вийшло сімнадцять.
З них чотири були «менеджер пише в особисті повідомлення Іванні з фінансів і чекає». Ще три — «дивимося в табличку, яку оновлює інша команда, але не завжди».
Поки я не описала це чесно, я думала, що автоматизую «пʼять кроків». Після опису стало ясно: спочатку треба прибрати чотири блокери і тільки потім говорити про автоматизацію.
Заповнений шаблон я ще закидаю в ChatGPT або Claude з промптом «розклади це на трирівневу архітектуру: інтерфейс, логіка, дані». Безкоштовний другий мозок, який бачить дірки в моєму описі краще, ніж я сама.
Як розподілити відповідальність за RACI
«Оунер процесу» в одному екземплярі не масштабується — тому для автоматизації я виділяю три ролі з чіткими A в RACI: process, data, tech. Спочатку я цього не робила.
Я фіксувала ролі максимально просто — «учасники» плюс «оунер процесу». Швидко стало зрозуміло, що це плутає команду.
Бо «оунер» у моєму уявленні — це той, хто приймає рішення про логіку. А «учасник» — той, хто робить кроки. А де поміж них той, хто володіє даними? А той, хто має апрувити запуск? А кому ставити в копію, коли щось зламалося?
Я перейшла на класичний RACI:
- Responsible — хто фактично виконує дію.
- Accountable — хто несе відповідальність за результат. Одна людина на одну дію.
- Consulted — з ким радимося до прийняття рішення.
- Informed — кого інформуємо після факту.
Для процесу автоматизації я виділяю три наскрізні ролі, у кожної свій Accountable:
- Process owner — за результат процесу в цілому. Якщо щось ламається — прокидається ця людина.
- Data owner — за якість даних у Source of Truth. Часто це інша людина, ніж process owner.
- Tech owner — за сценарій у Make / n8n, інтеграції, токени. Ще одна людина.
Класична помилка — повісити всі три на PM, який автоматизацію зібрав. Це не масштабується. Якщо я зникаю на тиждень у відпустку, сценарій не повинен мовчки деградувати. Якщо тобі складно назвати конкретну людину для кожного з трьох A — це сигнал, що процес ще не готовий.
Як налагодити Source of Truth
Source of Truth — це не таблиця. Це домовленість.
Це місце, з якого автоматизація бере актуальний стан. Якщо якихось даних там немає — для системи їх не існує. AI не додумає, Make не запитає у Колі в DM.
В одному процесі може бути кілька SoT — для різних типів даних. У нас в Projector для онбордингу студентів це виглядає приблизно так:
- Контакти й комунікація — CRM.
- Прогрес і активність студента — LMS-база.
- Конфігурація курсу (тарифи, дати, ментори) — Notion.
- Стан підготовки контенту — Notion канбан борд курс-менеджерів.
Кожен з цих SoT має свого data owner і свої правила оновлення. Коли я будую автоматизацію, що зачіпає, скажімо, три з них — я фіксую: звідки читаю, куди пишу, де єдина правда на випадок конфлікту.
Тест трьох питань
Для кожного SoT я перевіряю три речі:
- Хто оунер даних? Конкретна людина, яка відповідає за актуальність.
- За якими правилами дані оновлюються? Регулярність, тригери, відповідальні за оновлення.
- Що вважається актуальним станом? Останній запис, певне поле, певний статус.
Не відповідаєш на одне — маєш проблему. Моє правило: якщо я не можу за 30 секунд відповісти на питання «де живе актуальна версія цього поля?» — у мене немає SoT. У мене є кілька кандидатів на нього.
Чотири типові пастки
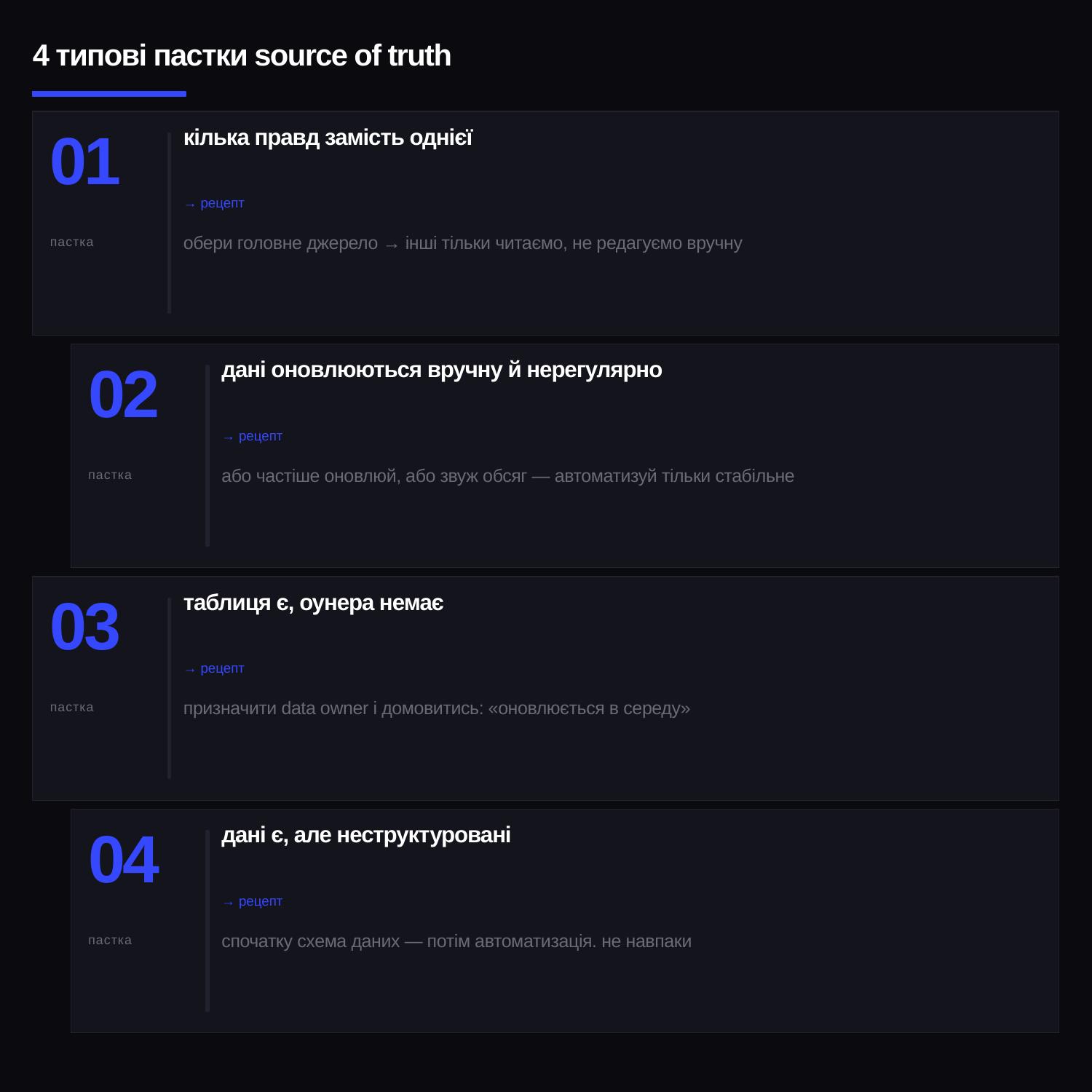
Найчастіша причина зламаних автоматизацій — SoT. Не Make, не API. Симптоми завжди ті самі:
- Кілька правд замість однієї. Один статус живе одночасно в Notion, Sheets і CRM. Кожна версія «нібито актуальна». Лікується вибором головного джерела і позначенням інших як похідних — їх тільки читаємо, не редагуємо вручну.
- Дані оновлюються вручну й нерегулярно. Сценарій працює зі станом, який застарів. Лікується або частим оновленням, або звуженням обсягу — автоматизуємо тільки той кусок, де дані стабільні.
- Таблиця є, оунера немає. Хтось колись створив, усі додають записи, ніхто не відповідає за актуальність. Лікується вибором data owner і простою домовленістю про регулярність («оновлюється в середу»).
- Дані формально є, але неструктуровані. В одній колонці — статуси, тексти й цифри впереміжку. Це не SoT, це звалище. Лікується підготовкою схеми даних до того, як писати в неї автоматизацію.
Без чіткого SoT немає чого множити в масштабі. Автоматизація бере зі SoT саме той стан, який є — і саме його тиражує далі.
Як перевірити технічну реальність
Третина моїх «спроєктованих» сценаріїв вмирала саме на цьому етапі. API в більшості випадків був — а от з доступами, токенами й лімітами я будувала собі ілюзії. Цей розділ я раніше пропускала. І щоразу платила за це.
Перед тим як починати збирати сценарій, я перевіряю чотири речі:
- Доступи до інструментів. Не просто «у мене є акаунт», а конкретно: права запису, права читання, рівень адміністратора там, де потрібен.
- API і його обмеження. Не всі інструменти, які виглядають як «у нас є API», справді мають його у відкритому доступі. У деяких є ліміти на запити, які роблять автоматизацію економічно нерентабельною.
- Готові коннектори в Make / n8n. Чи є нативний коннектор, чи покриває він потрібні мені дії і поля. Часто буває: коннектор є, але потрібного методу в ньому немає, доводиться лізти в HTTP-модуль.
- Токени, ключі, доступи. Де зберігаються, хто ротує, на чий обліковий запис привʼязані. Критичні автоматизації я ніколи не привʼязую до особистого OAuth.
Окремо — безпека й приватність. Якщо автоматизація торкається персональних даних студентів — я фіксую, через які сервіси проходять дані, де лежать логи, скільки часу зберігаються. Для EdTech з міжнародною аудиторією це базовий рівень перевірки.
Цей етап — про реалістичну перевірку: чи можу я взагалі побудувати те, що задумала, з тими доступами й інтеграціями, які зараз є. У моєму досвіді приблизно в третині випадків відповідь — «не можу, треба спочатку домовитися про доступ або обрати інший шлях».
Як спроєктувати логіку MVP
Перший сценарій MVP має бути огидно простий — таким, який не страшно змінювати. Усе інше нашаровується ітераціями. Коли всі попередні кроки зроблені, я беру Figma або просто аркуш паперу і малюю блок-схему.
Три шари і Happy Flow
Перше, що я роблю — фіксую тригер зліва і фінальний результат справа. Це дві точки, між якими має бути прокладений шлях. Далі ділю майбутній сценарій на три шари:
- Інтерфейс. Де людина взаємодіє з процесом — форма, повідомлення, лист.
- Логіка. Що відбувається всередині — правила, перетворення, виклики AI.
- Дані. Звідки читаємо, куди пишемо, що перевіряємо.
Розділення допомагає не змішувати все в одному блоці й одразу будувати схему так, щоб її легко було перенести в Make / n8n.
Третій крок — Happy Flow. Найпростіший шлях без винятків. Кожен крок робить одну дію. Результат блоку — вхід наступного. Жодних «а що якщо», «а раптом», «а ось у такому випадку».
Це навмисне спрощення. Якщо я з першої ітерації намагаюся покрити всі крайні випадки — я або не запущу сценарій взагалі, або зроблю його настільки складним, що сама не зможу його підтримувати.
Уже коли Happy Flow намальований, я по черзі додаю гілки. Кожне розгалуження — окрема свідома відповідь на питання «без цієї гілки сценарій буде працювати неправильно?». Якщо «без неї він просто покриє менший відсоток кейсів» — гілка чекає на наступну ітерацію.
Межі: де система, а де людина
До запуску я фіксую три речі: що довіряємо системі, де рішення залишається за людиною, і де потрібен апрув (система готує — людина перевіряє — система виконує).
Я використовую матрицю рішень по двох осях: зворотність (можна швидко відкотити дію?) і вплив (на скількох людей або скільки грошей вона впливає?). Беру кожен крок процесу і проганяю через цю матрицю:
- Низький вплив + зворотна — повністю автоматично. Наприклад, оновлення тегу в CRM.
- Високий вплив + зворотна — автоматично з логом і нотифікацією. Наприклад, відправка внутрішнього звіту.
- Низький вплив + незворотна — автоматично з затримкою. Я даю собі вікно «можна скасувати».
- Високий вплив + незворотна — апрув людини. Наприклад, відмова клієнту в B2B-партнерстві, нарахування знижки, видалення даних.
На старті MVP я свідомо тримаю більше точок контролю, ніж потрібно. Це нормально. З часом, коли автоматизація показує стабільний результат, частину апрувів я прибираю.
Автоматизація, яка через рік ходить через ті ж самі апрува, — це вузьке місце, яке всі вже звикли терпіти. Точки контролю — це допоміжні колеса. Знімаються поступово, в міру того, як автоматизація доводить, що варта довіри.
Чек-лист, який я проганяю перед Make / n8n
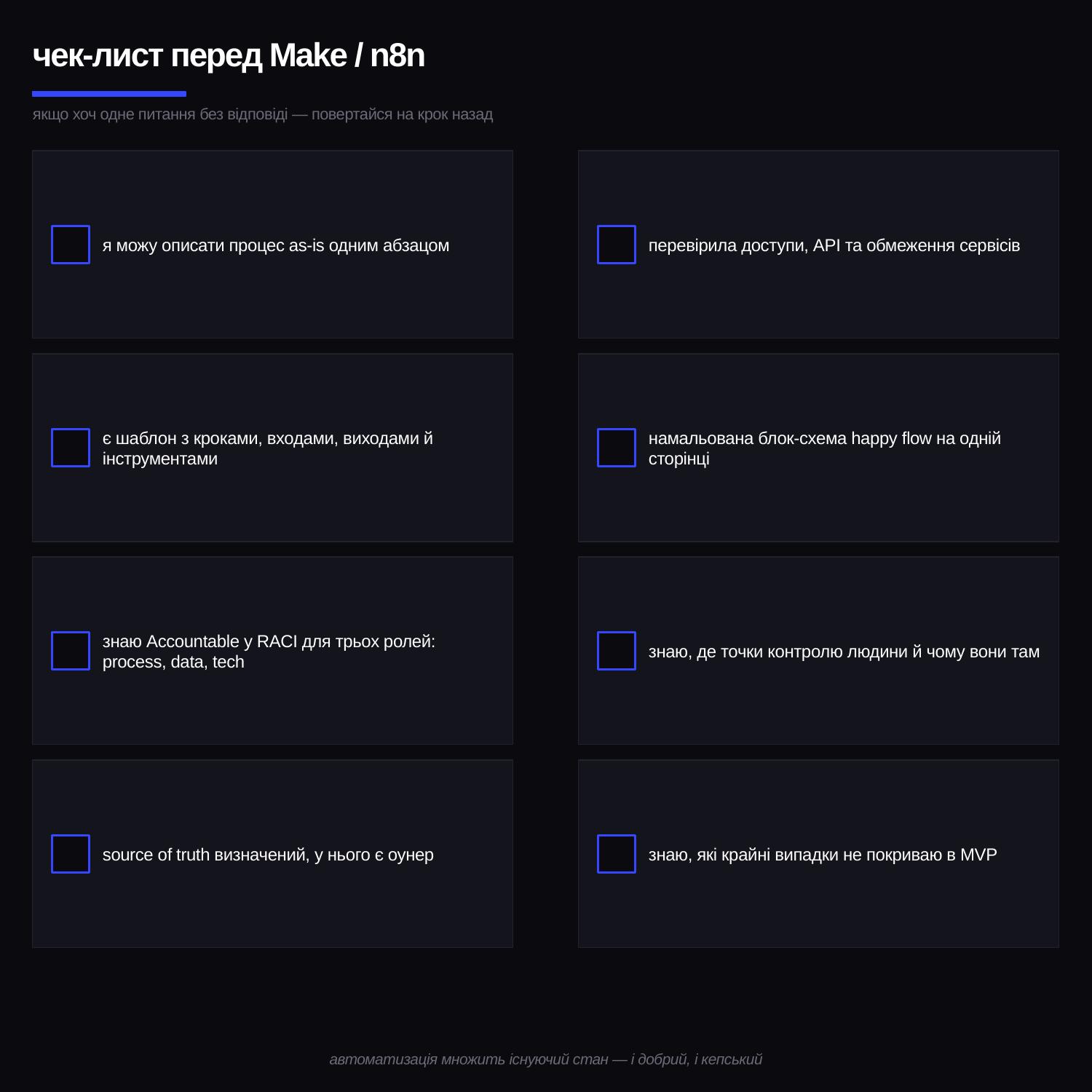
Перед тим як відкрити Make / n8n, я проходжу по цьому списку. Якщо хоч на одне питання не можу відповісти — повертаюся на крок назад.
- Я можу описати процес as-is одним абзацом.
- У мене є шаблон з розписаними кроками, входами, виходами й інструментами.
- Я знаю, хто Accountable у RACI на кожну з трьох ролей: process, data, tech.
- Source of Truth визначений для кожного типу даних, у нього є оунер.
- Я перевірила доступи, API та обмеження сервісів.
- Намальована блок-схема Happy Flow на одній сторінці.
- Я знаю, де точки контролю людини й чому вони там.
- Я знаю, які крайні випадки свідомо НЕ покриваю в MVP.
Перша версія цього шаблону була написана злою рукою після того, як моя перша автоматизація прожила менше дня. З того часу я перебудувала його кілька разів, але ключова ідея не змінилася: підготовка коштує дешевше, ніж відкат.
Якщо вибирати між «два дні на реалістичний опис процесу» і «два дні на гасіння продакшн-пожежі» — підготовка завжди виграє. І не тільки за часом. Вона виграє ще й за нервами, довірою команди й моєю особистою впевненістю в тому, що я будую.
Автоматизація не виправляє хаотичний процес. Вона робить хаос швидшим, дорожчим і помітнішим. Тому моє нудне-але-чесне правило: поки я не можу пройти власний чек-лист — автоматизація почекає. Поки я можу — він спрацьовує з першої спроби.
автоматизуйте свою рутинуна курсі

| досвід | не обов'язковий |
|---|---|
| старт навчання | 08.09.2026 |
| кількість місць | 25 |
| тривалість курсу | 10 тижнів |
| інструменти | потрібна підписка на Claude |
| куратор | Олексій Павленко |
перший крок за вами
розширюйте свої можливостізавдяки новим знанням
грамотна автоматизаціяпідсумуємо
- Як зрозуміти, що процес готовий до автоматизації?
- Що таке ICE-скоринг і як його використовувати для вибору першої автоматизації?
- Що таке Source of Truth і чому без нього автоматизація ламається?
- Як вирішити, які дії довіряти системі, а які залишати людині?
ще цікаведля вас


Як боротьба з рутиною привела моушн дизайнера до нової ШІ-ролі







